
1 Billion DB Records Update Challenge - My Approach

Recently I came across a fascinating engineering challenge. The challenge is about adding a new column to a table and updating its value. But the main catch here is the table contains 1 billion records. I tried Googling this for a solution, but it does not go as a satisfactory solution. So I have decided to write this post and explain my approach and ask for your opinions regarding improvements and drawbacks to my approach.
One thing I would like to mention is that I didn't say that my solution is perfect. It might have several drawbacks, and I would especially thank you if you pointed them out.
Problem
You have a transaction table with approximately 1 billion records. It contains a transaction column with a unique transaction number for every record. Now in the new column, utr_number is added to this table. Our task is to reconcile this table by updating utr_number, which is currently set to null.
In order to get a UTR number, we are given an API that accepts a transaction ID and returns a UTR number. This API takes around 100 ms to respond and does not guarantee 100% uptime.
Constraints
1B records
API call per record to fetch UTR. Rate limits to 10,000 calls / min
Avoid database overload
Avoid application downtime
NULL
UTRfield initially
Let me tell you my approach for this.
Overall Flow
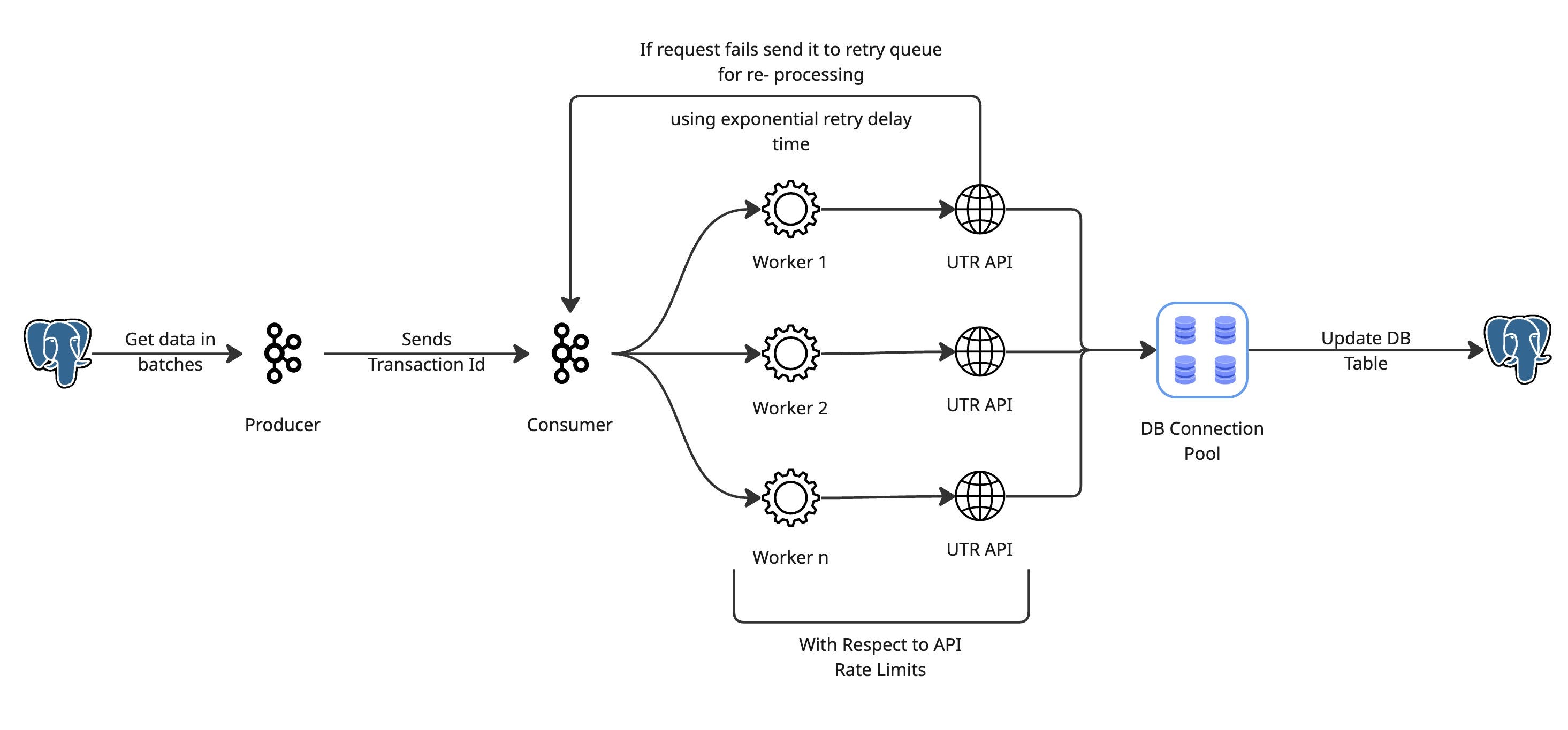
Batch Processing
Instead of loading 1 billion records at once for processing, we can load them in batches. We can process the first 5000 records and then the next 5000. This number is completely configurable according to your server resources.
Message Queue
As we are dealing with too much data, the first thing that comes to my mind is to use a message like Kafka. Not for long-term use but for parallelism, retry mechanism and monitoring. Because, as mentioned, the API might not provide 100% uptime. So in order to retry failed updates, we can use the exponential mechanism.
This is how data will flow:
Fetch the 1st N number of rows from the database.
Push them to Kafka.
Let the consumer handle them on the other side.
Sleep for some time.
Repeat with the next N number of rows.
Concurrent Consumer
On the consumer side, instead of processing records one by one, we can create several worker threads. They will call the external API concurrently at the same time. We must care about not spawning too many threats, as it may degrade application performance.
Thread Pool
A thread pool is a solution for that. We will use a thread pool with a fixed number of threads.
Rate Limiting
Each worker thread will call the API. This may lead us to another problem of rate limits. As per the constraints, the API can serve 100K requests per minute. So while making concurrent requests, we must first check that we are not violating rate limits. For this we can add a token bucket rate limiting layer on our side. Each thread first needs to check if we are under the rate-limiting boundary or not before hitting the API.
Exponential Retry Mechanism
In case of any downtime or any type of error from the API, we must retry the updating process after some time. For this we can use an exponential delay retry mechanism. Let's understand this with an example.
A failed request will be retried after 2 mins.
If it fails again, we will retry it after 4 mins.
If it fails again, retry after 8 mins.
and so on.
Concurrent Updates
Just like we used a thread pool to create several threads for call current processing, we will use a database pool or concurrent updates. For every thread that brings us a UTR number, we will request a connection from the thread pool to update that UTR in the database. This will prevent us from flooding write operations to our database.
Total Time Required
Total records 1,000,000,000
API rate limit 10,000 requests/min
Batch size 5,000 records
Sleep time per batch 5 seconds
Number of batches
1,000,000,000 / 5,000 = 200,000
Total Sleep Time
200,000 batches × 5 seconds = 1,000,000 seconds
Requests per Hour
10,000 × 60 = 600,000 requests/hour
Requests per day
600,000 × 24 = 14,400,000 requests/day
Time
69.4444 days
Sleep + Processing Time
81 DaysMy question for you
What are drawbacks in my approach?
What wrong I’m doing?
If API fails for a long time a lot of messages will enter retry queue. How to solve it?
Any suggestions?
Suggestions by readers:
A key bottleneck lies in the step where the system calls the UTR API. No matter how efficiently earlier stages are optimized, the overall performance remains constrained by the API’s rate limit. This could be mitigated if the API supported batch requests — allowing multiple transaction IDs to be queried in a single call instead of one at a time.
Final Thoughts
So I don't have too much experience working with large-scale systems; I just wanted to try a solution for this problem. If you can tell me any other approach or any suggestions in my current approach, I can update this blog accordingly. I also keep exploring new things and posting them here, so you can subscribe to this newsletter for free, and all my new posts will reach your inbox.
I think your solution has a bottleneck at the step where it calls the UTR API. Regardless of what you do before calling the API, it is still limited by the rate limit. Can the UTR API return a list if we input a list of transaction IDs?