


I Made a Configurable Rate Limiter… Because APIs Can’t Say ‘Chill’


I made a configurable rate limiter. In this post I am going to talk about that. We will discuss its architecture and how it works.
Rate Limiter
Rate limiting is a technique that controls the number of requests that can be made to an API within a specific interval of time. Although it is not a very new concept, it has been used for a long time. But I haven't made a traditional rate limiter; instead, I made a configurable rate limit.
Configurable Rate Limiter
A configurable rate limiter perform all the tasks of traditional rate limiter but also allow you to specify different rate-limiting rules for different APIs. Which means that one API can serve 1000 requests per minute and another can serve 100 requests per minute based on predefined rules.
Services
My implementation of this rate limit contains several services:
1. Limiter Service: It coordinate with client and process limiting with appropriate algorithm.
2. Token Bucket: A simple and minimalistic rate limiting algorithm.
3. Fixed Window Counter: A slighting window based rate limit algorithm (but not exactly sliding window).
4. Sliding Window Counter: An algorithm with all the improvements that Fixed Window Counter lacks.
5. Limiting Rules: A set of rate limiting rules.
6. Redis: The main database for the implementation of this whole architecture.
7. Slack: Notification platform to get notified when something wrong.
So after reading a small summary of all the services, you should look at the below flow architecture, which will make things more clear for you.
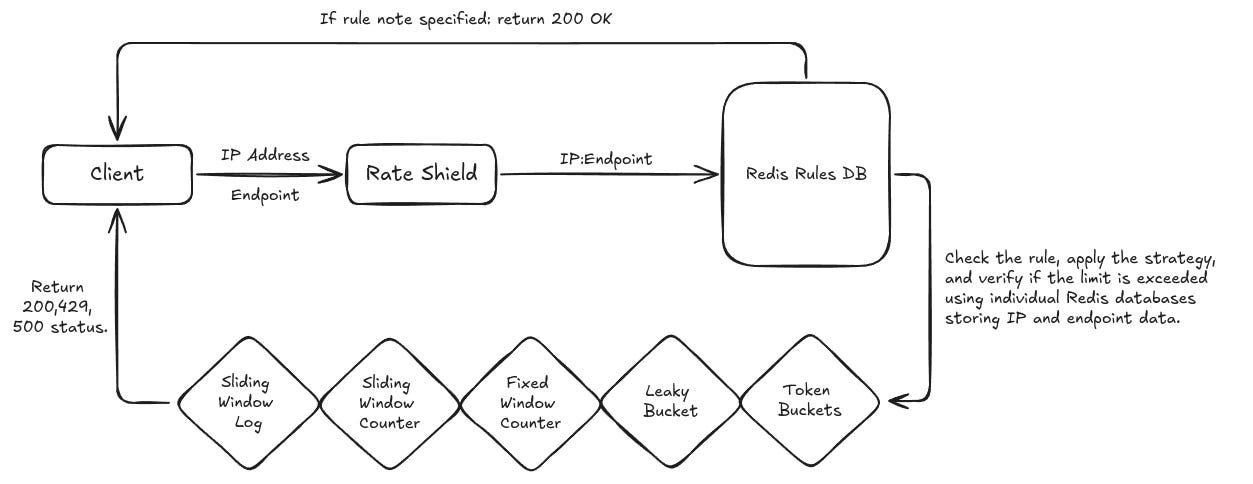
Rules:
Firstly, I am storing rate-limiting rules in Redis. A rule structure looks like this. It tells us which strategy to follow on which endpoint. It also contains some additional information related to that specific strategy.
{
"strategy": "TOKEN_BUCKET",
"endpoint": "/api/v1/resource",
"http_method": "GET",
"allow_on_error": true,
"token_bucket_rule": {
"bucket_capacity": 1000,
"token_add_rate": 10
}
}
In our case of the token bucket algorithm/strategy we require capacity of bucket and token add rate. Capacity tells us how many requests per minute can be made to that API and how many tokens will be added each minute to that bucket.
Another example with sliding window rate limiting strategy may look like this.
{
"strategy": "SLIDING_WINDOW",
"endpoint": "/api/v1/resource",
"http_method": "GET",
"allow_on_error": true,
"sliding_window_counter_rule": {
"max_requests": 100,
"window": 60
}
}
Limiter Service
Now we have limiter service that is a central part of this architecture. It gets the IP and endpoint from the client and processes rate limit limiting logic by fetching the appropriate rule.
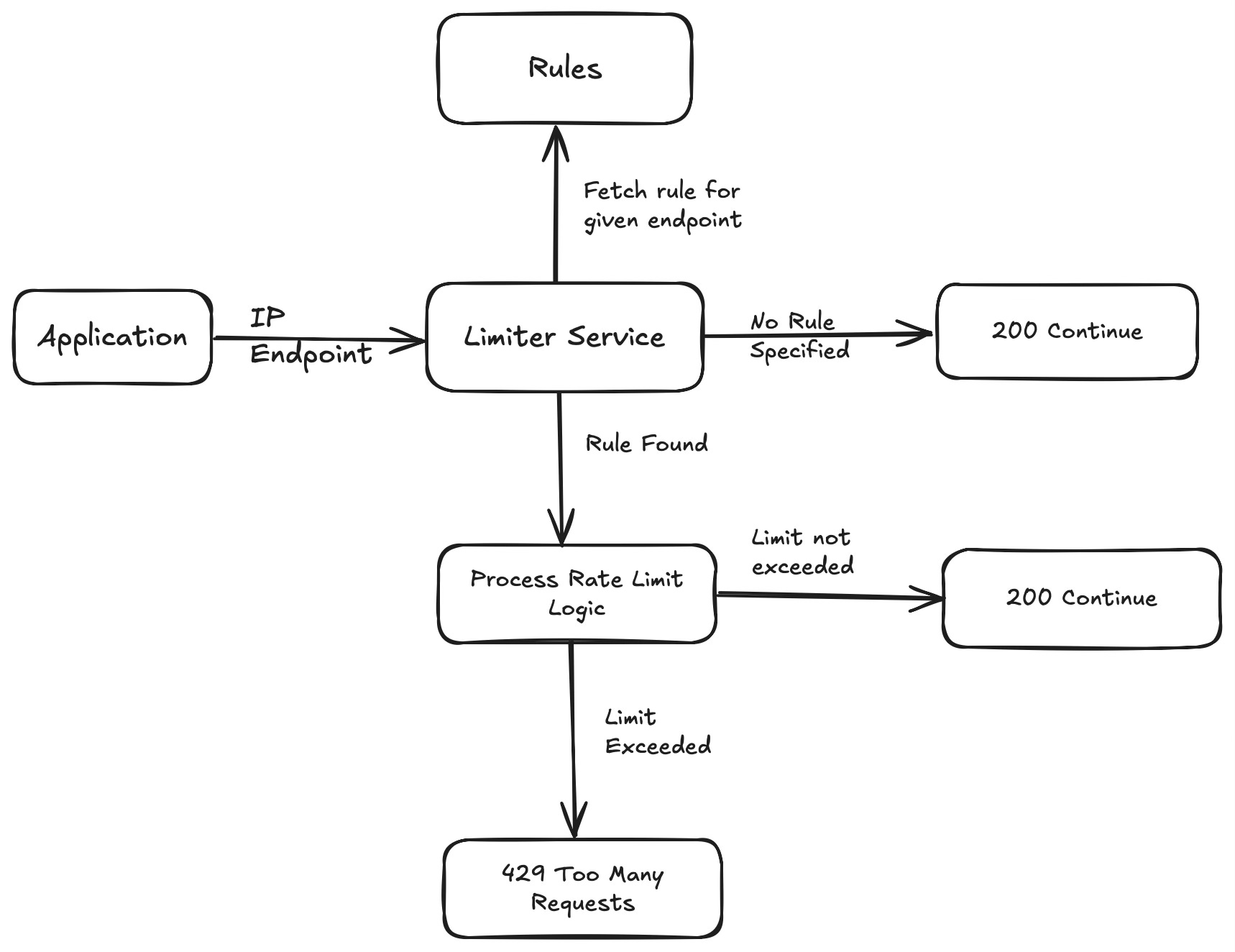
Flow
Limited service receives IP and endpoint, then it fetches the rule from the database. Let's suppose the rule includes a token bucket algorithm.
If there is no existing bucket, which means that the user is trying to access this API for the first time, we will create a bucket and store it in Redis with a TTL of 1 minute.
Check if there is already a bucket that exists in Redis. If yes it means that user had already accessed this API in last one minute and we will decrease remaining tokens by 1.
If there are zero tokens available, this means that the user has already done a request to this API; hence, we have to throw a 429 Too Many Requests error.
This was the case for the token bucket algorithm, but for other algorithms, this might differ. We will not cover that in this post, but I will surely create another post for that, and you can always go to Google and search for other rate-limiting algorithms.
Database & Storage
I am using a combination of Redis single node and cluster. These two serve different purposes.
Redis Single Node: Single node will contain all the rules. As this data will be limited we don't need a cluster for that.
Redis Cluster: On the other hand, a new entry for every user will be created in Redis. Which will require a lot of scalability. That's why we are storing all the data such as token buckets, sliding window and fixed window related data in Redis cluster that allows you to scale horizontally. So whenever you realize that you are running out of resources, you can always add one more node to the cluster.
Optimizations
There is one optimization that we can do in this architecture. If you have another optimization idea, you can always comment on it down, and I will include it in this post.
Why access redis every time for rules?
As we know, rules are something that won't be updated very regularly. They will be updated whenever we want, so why access them every time from Redis? So what I have done is I have implemented a function that globally stores rules in a map whenever my application starts. This way I do not need to go to Redis every time for rules; instead, I can look into that language-specific map.
How to update local rules map automatically?
There is no automatic mechanism for updating these rules locally. But you can use Redis Channel. It is a mechanism that will send you a callback whenever something updates in Redis. Simply listen to this callback via a thread in your code and update the local rules map whenever you receive a callback.
Frontend
I have also created a front-end application that you can use to modify rules.
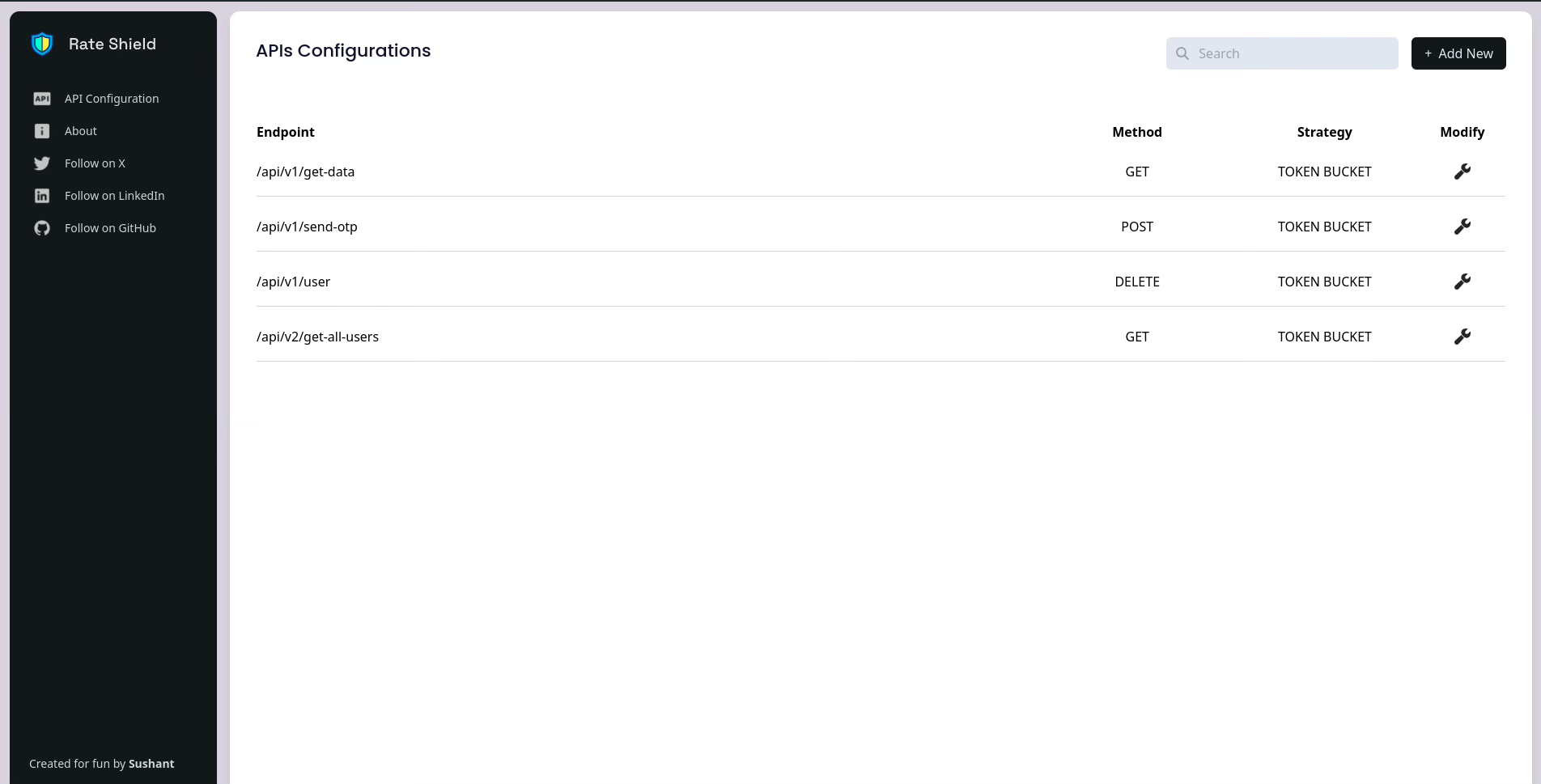
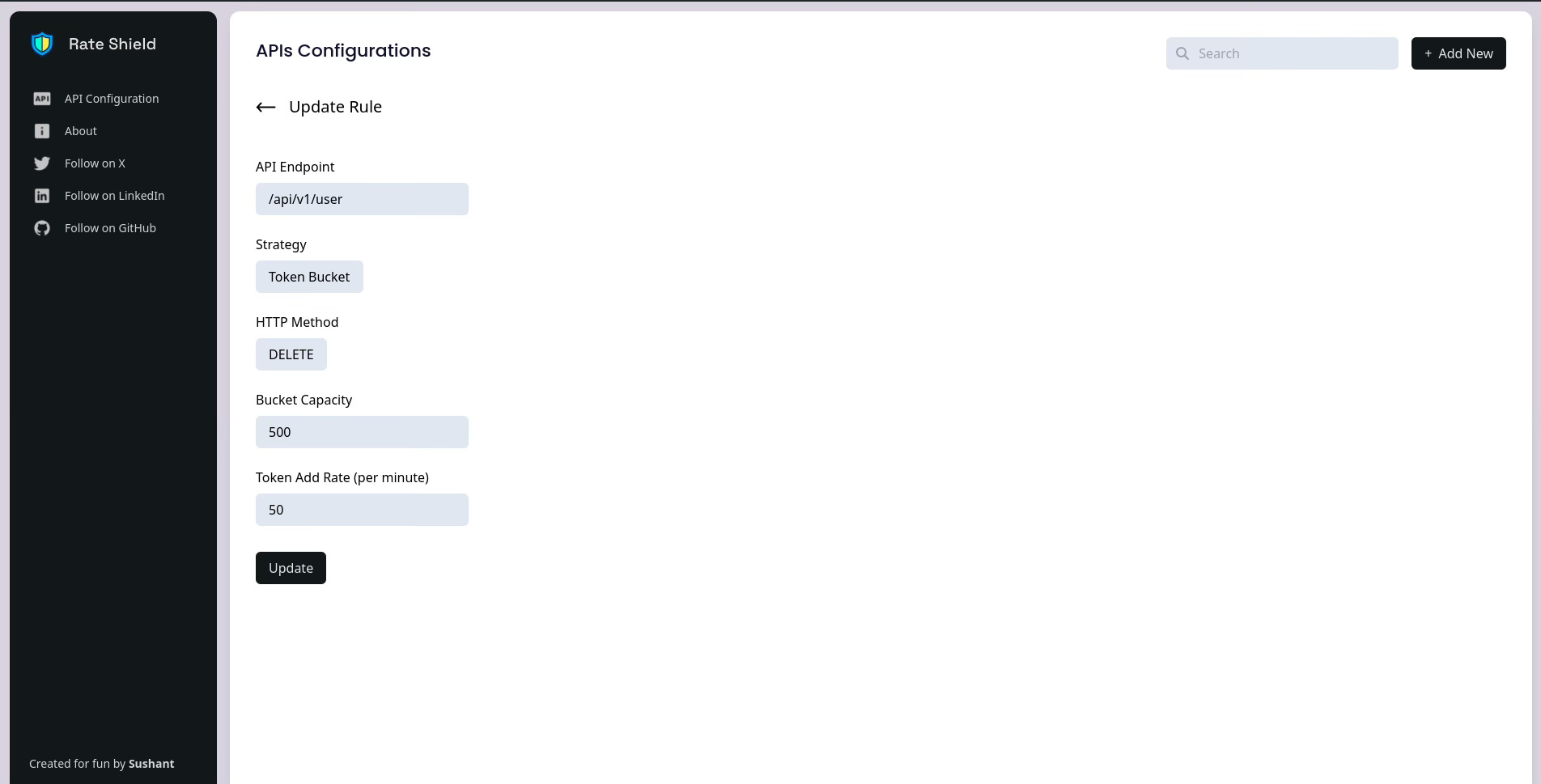
Source Code
Here is the source code for this configurable rate limit in case you want to go through it.
Limiter Algorithms Implementation
In the next post I will discuss and show how you can implement Token Bucket, Fixed Window Counter and Sliding Window Counter Algorithms with code example. If you want to get notified about that post, you can subscribe to my newsletter that is completely free.
Also Read
Kafka Delay Queue: When Messages Need a Nap Before They Work
Thank You
I am always eager to learn from my mistakes so if you think that there is a mistake or improvement in this architecture please comment it down. Thank you, and have a nice day.