

Hi,
It's been a long time since I wrote something in this newsletter. Recently I was learning about language parsing and abstract syntax trees. After getting some knowledge about this, I decided to write a JSON parser from scratch.
Parsing:
It is the process of analysing the structure of a string (basically any programming language syntax). Parsing helps us to determine the meaning of the text. Writing a parser for a programming language is a very complex task because programming languages generally have a lot of keywords and syntax rules. Handling all those syntax and keywords can be overwhelming and highly difficult. But in the case of JSON we have a very limited number of keywords and syntax rules. So writing a JSON parser is a relatively easier task.
Tokenization:
It is the process that is done before parsing. Tokenization means breaking down and categorizing string of character into smallest units called tokens. Below table will give you a solid idea of what tokens look like.
JSON:
{
"name": "iPhone 6s",
"price": 649.99,
"isAvailable": true
}
Token : Type
------------:--------------
{ : BRACE_OPEN
name : STRING
: : COLON
iPhone 6s : STRING
, : COMMA
price : STRING
: : COLON
649.99 : NUMBER
, : COMMA
isAvailable : STRING
: : COLON
true : TRUE
} : BRACE_CLOSE
Once tokenization break down string into tokens than these tokens are given to Parser which created an Abstract Syntax Tree. We will discuss it later in this post. But your 1st step is to create a tokenizer.
Writing The Tokenizer:
Now let’s get into the code part where we tokenize a JSON string.
I wrote a function called Tokenize which takes a JSON string and returns a list of tokens. It loops through the string, character by character, and breaks it down into meaningful pieces like {, "key", : or 123. These pieces are what we call tokens.
Here’s the full code, broken down step by step.
We will first start with creating some basic types for all the tokens.
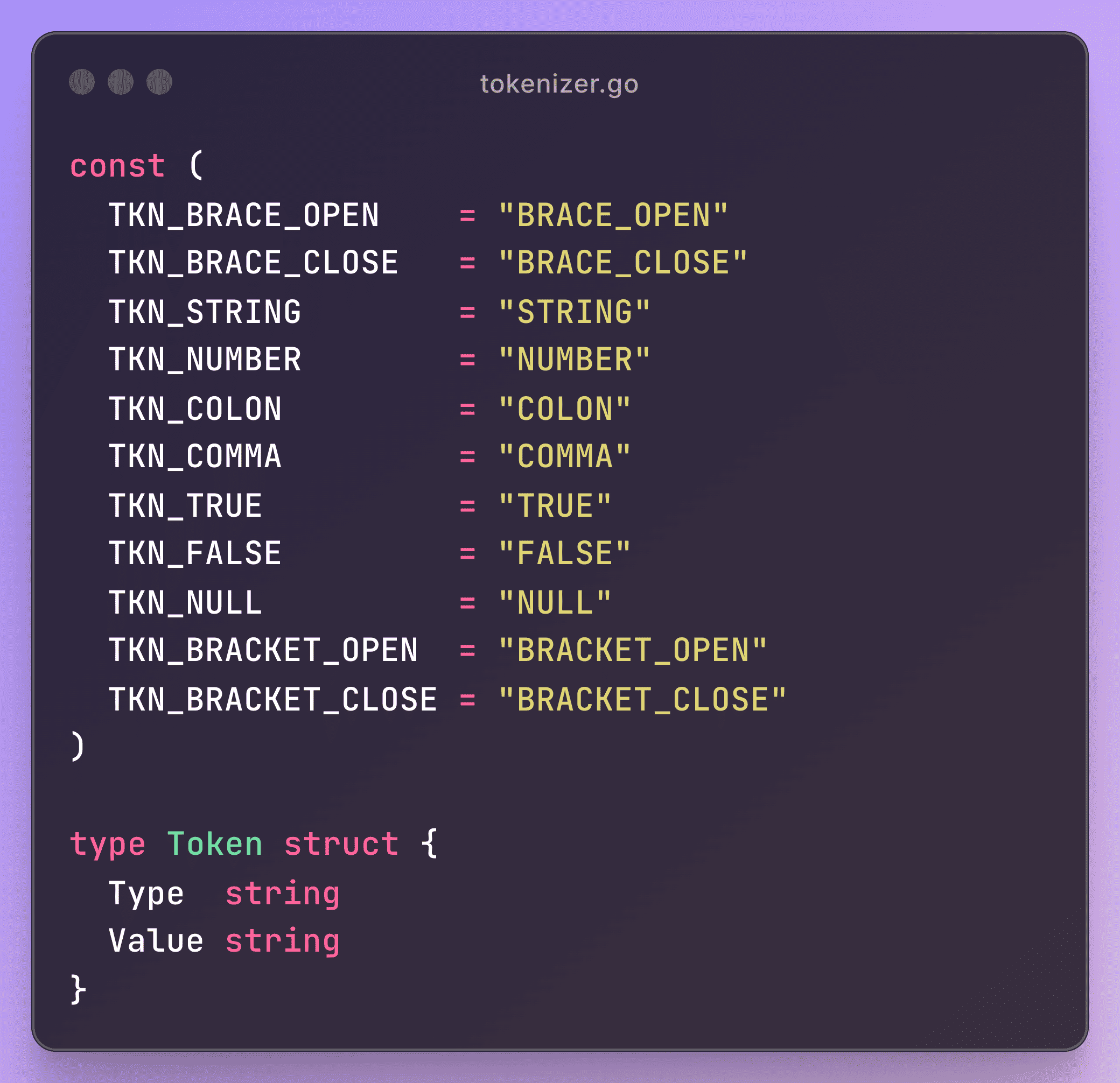
We start with a current pointer to keep track of where we are in the string. stringLength helps us not go out of bounds, and tokens is the slice where we’ll collect all the tokens we generate.

Skipping Whitespace
We loop through the entire string. If we hit whitespace, we skip it because whitespace doesn't matter in JSON.
Switch through known single-character tokens
Than we handle all the simple symbols here. These don’t need much logic — just push them to the tokens list and move on.

Handling Strings
When we encounter a ", we start reading a string. We look for the closing quote, while also making sure to skip escaped quotes like \". If the string is never closed, we throw an error. Otherwise, we extract the string and add it as a token.

Literals and Numbers
We check for true, false, and null first. If we see one of these keywords, we push it to the tokens list and jump ahead accordingly.

Numbers (slightly tricky)
JSON numbers can get complex. They might contain decimals, negative signs, and exponential notation (like 1.2e+10). We carefully walk through each character to build the number string. I also added validations to reject bad formats like 00, multiple dots, or missing exponent digits.

If nothing matches
If none of the above matched, the character is invalid in JSON — so we just throw an error.
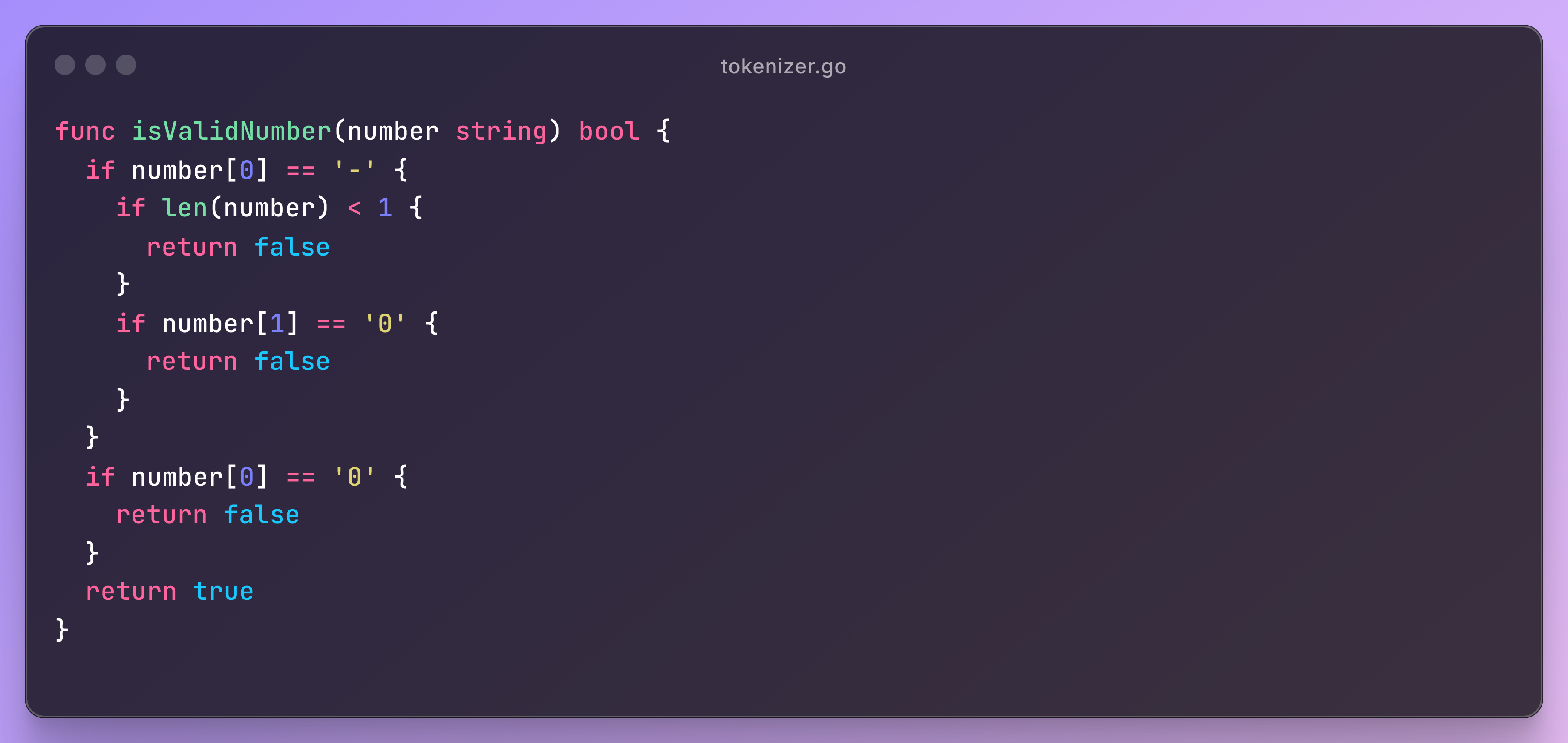
Number validation helper
This method is used to check for bad leading numbers in JSON.

Printer
This just prints the list of tokens in a nice readable format. Super handy when testing your tokenizer.
Tokenization Output
If we give below JSON to our tokenizer we will get following output.
{
"name": "iPhone 6s",
"price": 649.99,
"isAvailable": true
}
Now our JSON is nicely tokenized and each character had been given its appropriate token type.
Complete Tokenizer Code: GitHub
Parsing & AST
We have now created a tokeniser that converts JSON objects to tokens. The next step is to create a parser that can convert these tokens into an abstract syntax tree. But first, let's understand what an abstract syntax tree is.
Abstract Syntax Tree (AST)
It is a Tree structure that represent syntactic structure of source code. To learn more about it refer to this awesome article: https://dev.to/balapriya/abstract-syntax-tree-ast-explained-in-plain-english-1h38
Writing The Parser:

This is the base interface for all AST node types. Every node will implement the Type() method, which is a simple way to identify what kind of data (Object, Array, String, etc.) it holds.

This is the main function you call to parse the token stream.
It checks if there’s anything to parse. Then it initializes a
currentpointer (used as an index into thetokensslice).Delegates to
parseValue, which handles all the different types.

Basic safety check: if the current token is past the end, return an error.
Now comes the type-checking:
String token → wrap it in
StringNode.Number → parse into float64.
Booleans and null are direct mappings.
Delegates to specialized functions for objects (
{}) and arrays ([]).Anything unexpected = throw an error.

Skip the
{token.Initialize an
ObjectNode.Extract the key from the object and parse the value using the already written
parseValue()function.
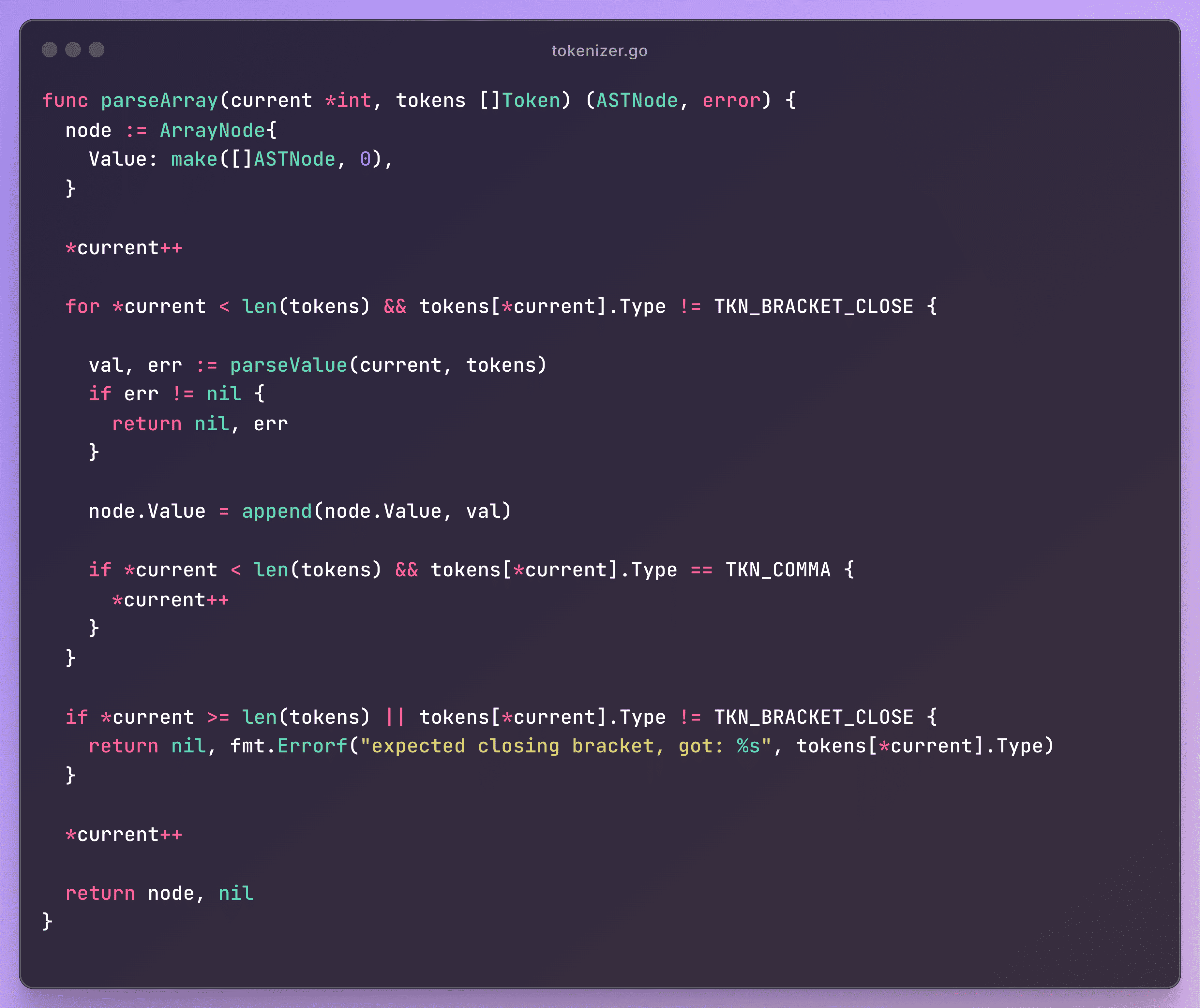
Start parsing array (skip the
[token).Loop through all values.
Each value is parsed with
parseValueand append value to initialized array.Ensure the array ends correctly with
].
Output:
Below is the output we will get if we parse the tokens of JSON that we used above.
{
map[isAvailable:{true}
name:{iPhone 6s}
price:{649.99}]
}Additional Challenge:
Try converting this AST node to native Golang data structure and use it.
Let’s Connect
I'm always willing to get to make new connections.
GitHub | LinkedIn | Twitter | Instagram
Source Code
Final Thoughts
So this was how we could implement a simple JSON tokenizer and parser from scratch. If you have any suggestions or doubts, you can always comment below. Consider subscribing to my newsletter to get notified for new posts.
You (correctly) note that this is a 'simple' json parser. It's probably worth (as you would get asked in a coding interview) what the trade-offs / limitations are. I'm not sure I have spotted them all, but the biggest ones I can see are memory usage (makes multiple memory copies of strings and numbers), GC pressure (it's allocating a whole bunch of small objects that probably won't be needed / kept around) and the fact that the whole json file needs to be read in to memory before you can start using it.
Can anybody spot any I've missed?