

This weekend I was diving deep into current programming. In order to learn that, I decided to write a threaded file compressor, which will not only compress files concurrently but also limit the memory usage. I have implemented this in GoLang, but these concepts can be implemented in any language.
What I’ve Developed?
I designed a tool that reads files in chunks and limits the overall memory used by introducing a memory-aware semaphore system. It also uses a pool of reusable buffers to make things even faster.
Each file is compressed using gzip, and the entire process is handled concurrently using worker goroutines—so it's fast and memory efficient.
Let’s Write Some Code
So I started by defining a simple configuration struct called CompressionConfig.

Let me break it down:
NumWorkers — This defines how many worker goroutines will run in threaded. More workers = faster compression (if you have CPU to spare).
MaxMemoryUsage — This is the upper memory limit for the compression process. It ensures we don’t overload the system while handling large files.
CompressionLevel — Standard gzip compression level (from 1 to 9). I defaulted it to 9 for maximum compression.
ChunkSize — Instead of loading entire files into memory, I read them in chunks. This defines how big each chunk should be.

Once I had the configuration ready, the next step was to define what a compression job actually looks like.
Here’s what each field does:
InputPath — The path of the file that needs to be compressed.
OutputPath — Where the compressed file should be saved.
FileSize — This can be useful for tracking and logging, although I didn’t use it heavily in this version.
Ctx — A
context.Contextthat helps with cancelling jobs cleanly (for example, if the user wants to stop the process midway).

After compressing each file, I wanted to collect some useful information about the outcome — so I created a CompressionResult struct:
Job — A pointer back to the original job, so I know which file this result belongs to.
Error — If something goes wrong during compression, this will capture it.
OriginalSize — Size of the file before compression.
CompressedSize — Size after compression — helps measure how effective the compression was.
Duration — How long the compression took.
OriginalChecksum / CompressedChecksum — (Not implemented yet in my version, but placeholders are ready!) These would help verify integrity — making sure the content isn’t corrupted during the process.
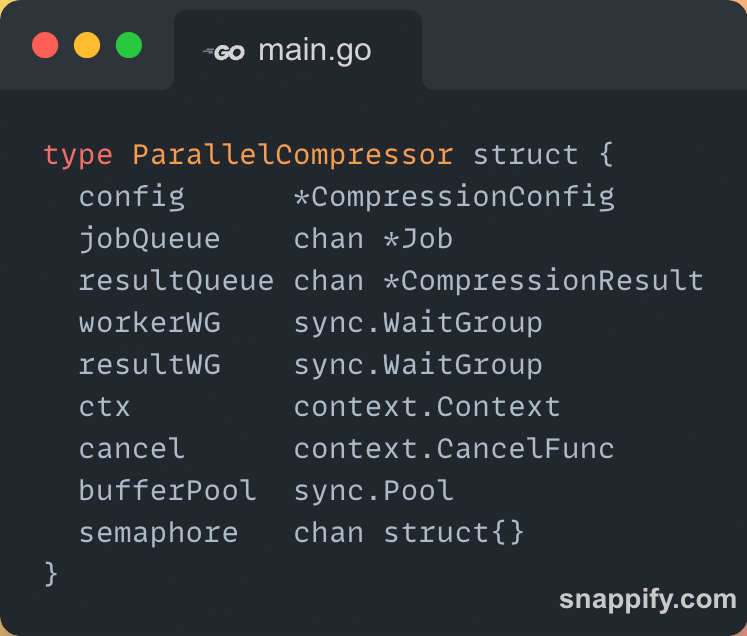
Now comes the heart of the whole system — the ParallelCompressor.
This struct holds everything needed to manage workers, jobs, memory, and results. Here's how it looks:
config — Holds the compression settings we defined earlier (like memory limit, chunk size, etc.).
jobQueue — A channel where all compression jobs are sent. Workers pick jobs from here.
resultQueue — After processing, workers push results here to be handled separately.
workerWG / resultWG — WaitGroups help us wait for all workers and result processors to finish cleanly.
ctx / cancel — Context used to cancel the whole operation (for example, on error or manual stop).
bufferPool — A pool of byte slices reused across jobs to avoid allocating memory repeatedly — very useful for performance.
semaphore — This is the clever part: it limits how many jobs can allocate memory at once, based on the configured memory cap. It’s how we enforce the max memory usage rule.

To wire everything together, I created a constructor function called NewParallelCompressor. This sets up all the internals for running parallel compression with memory limits.
If the user doesn’t set a number of workers, I default it to the number of CPU cores — which usually works well for concurrent workloads.
Next, I create a cancellable context. This gives me a clean way to cancel all running jobs in case of an error or user interruption.
The job and result queues are buffered channels to prevent blocking when producing or consuming tasks.
The bufferPool here is super useful. Instead of allocating a new byte slice every time I read a chunk, I reuse buffers from a pool — which reduces memory pressure and garbage collection overhead.
Finally, the semaphore is the key to enforcing memory limits. It limits how many buffers can be in use at the same time. If you set MaxMemoryUsage to 32 MB and ChunkSize to 2 MB, only 16 buffers can exist at once.
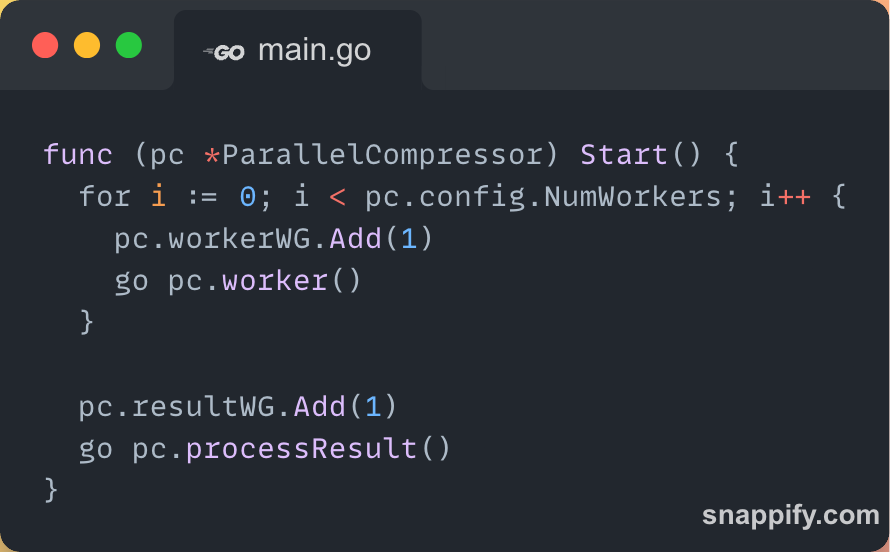
Once the ParallelCompressor is initialized, I needed a way to kick off the actual work — spinning up workers and setting up result processing.
That’s what the Start() method is for:
I launch multiple worker goroutines based on the number of CPUs (or user-defined workers).
Each worker picks up jobs from thejobQueueand compresses them.pc.workerWG.Add(1)increments the WaitGroup counter, so we can later wait for all workers to finish before exiting.Then I start one goroutine to handle results — basically, to consume from the
resultQueueand print any errors or logs.

Let’s talk about the worker — the actual unit that performs the compression. Each worker runs in its own goroutine.
First, I make sure that when a worker exits, it signals the WaitGroup so we know it's done.
The worker continuously listens for jobs from the jobQueue. If it receives nil, that means we're done — time to exit.
Once it gets a job, it processes it using processJob(), which handles reading the file, compressing it, and storing the result.
The result (success or error) is then pushed to the resultQueue. If the context is cancelled before that, the worker exits early.
The outer select block ensures the worker is also listening to the cancellation signal. This way, if something goes wrong, all workers can exit cleanly without finishing the remaining tasks.

The actual compression logic for each file lives inside the processJob() function. Each worker calls this when it picks up a job.
I start by creating a new CompressionResult tied to the job we’re processing.
I track how long the compression takes. Once the function finishes, the duration is recorded.
Next, I open the input file. If it fails, I capture the error in the result and return early. I store the original file size so I can compare it later with the compressed version.
Now, I prepare the destination file where the compressed data will go and send both files to compress method for compression.
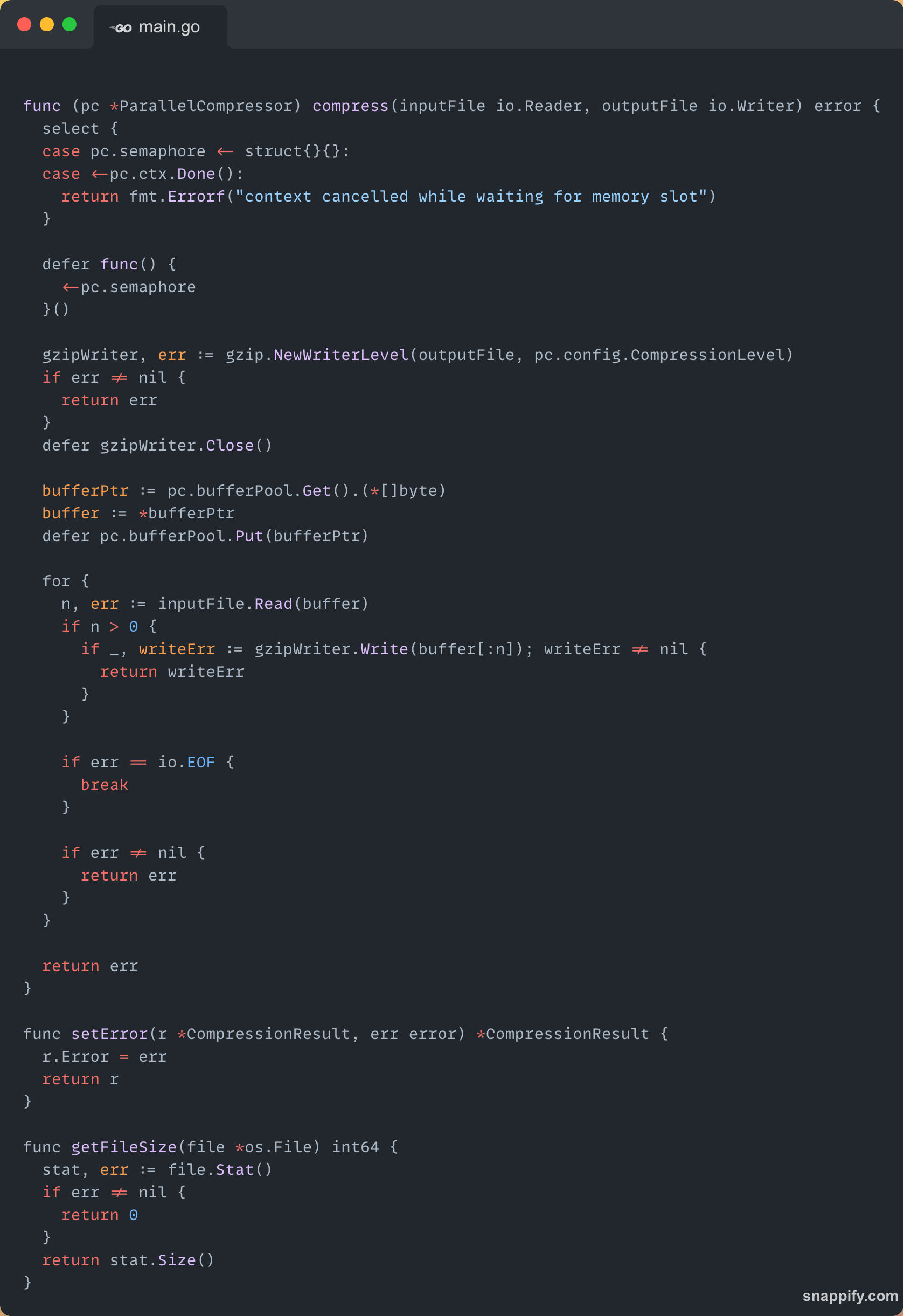
The actual compression logic happens inside the compress() function. This is where chunks are read from the input file, compressed using gzip, and written to the output file — all while respecting memory limits.
Before I start compression, I acquire a memory slot from the semaphore. This ensures that only a safe number of jobs are allowed to allocate buffer memory at a time, based on the total memory cap.
If the context is cancelled (maybe due to error or shutdown), the function exits early.
Once the job is done, I release the slot back so others can use it. Simple and effective memory control.
I use Go’s built-in gzip writer to handle the compression. The compression level is customizable through the config.
I pull a buffer from the pool instead of allocating a new slice. This avoids extra allocations and speeds things up. After the work is done, the buffer is returned to the pool.
I read the input file chunk-by-chunk and write the compressed data to the output. The loop continues until we hit EOF (end of file). If any read/write error occurs, we return early.
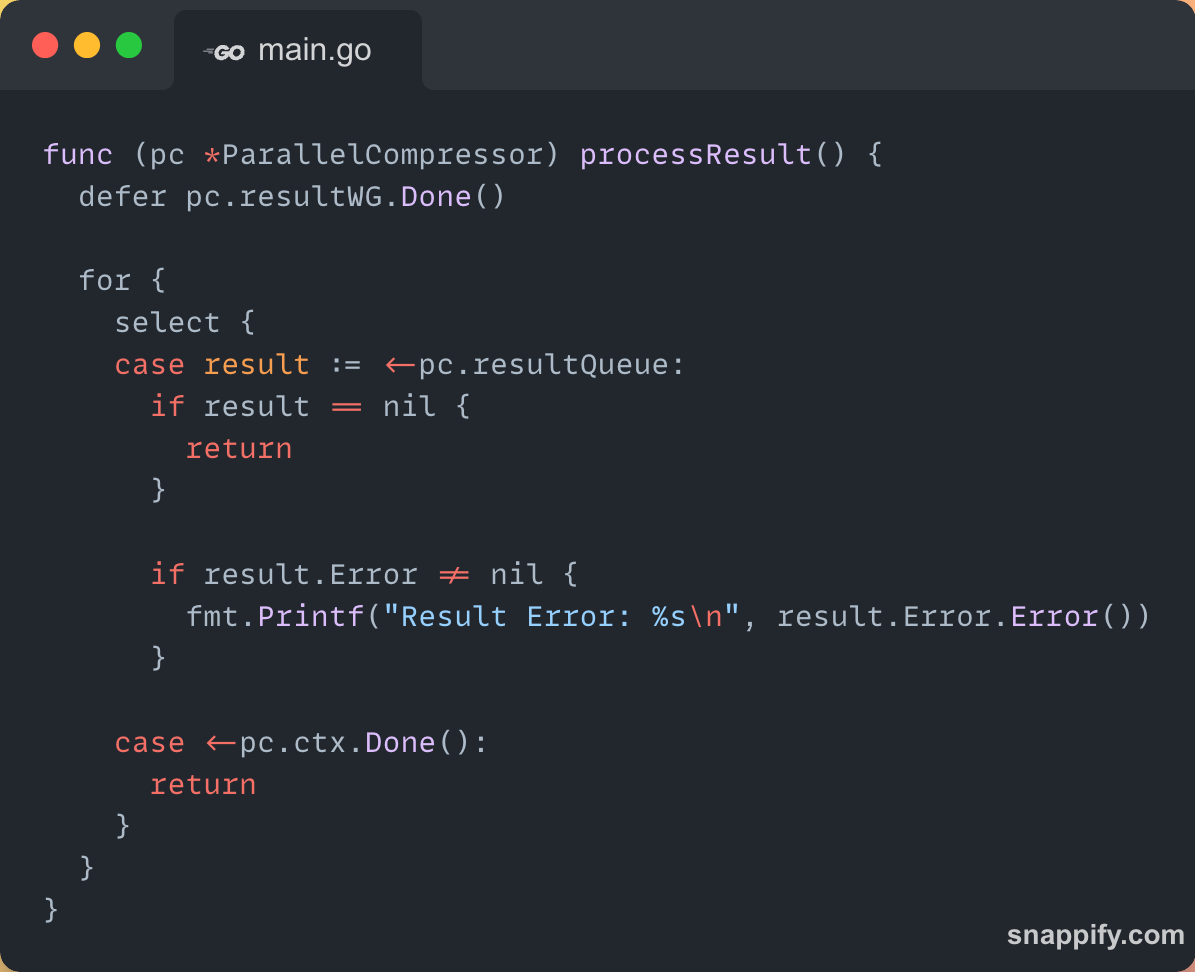
Once the files are compressed, I needed a way to handle the results — whether successful or failed. That’s what the processResult() function is built for.
As with the workers, I use a WaitGroup to track when the result processor finishes. This defer ensures it's marked done at the end.
The result processor runs in a loop, constantly listening on the resultQueue. If it receives nil, it knows the queue has been closed and it’s time to exit.
Right now, I only print errors — but this is the perfect place to extend things later. I could log stats, show compression ratios, update a UI, or store results in a database.

Here is a simple function that prints how much memory our program used for execution.

Finally, here's the main() function — where everything comes together and the tool actually runs.
I start by printing the memory usage before compression. This helps me compare how much memory is used during the process.
Here, I define the configuration:
8 workers
32 MB total memory limit
gzip level 9 for max compression
reading files in 2MB chunks
I initialize and start the compressor — this spins up the workers and the result processor.
Next, I prepare a list of files to compress. In my case, they’re just test PDFs named book1.pdf to book13.pdf.
I start a timer to track how long the whole compression process takes.
For each file, I create a Job and push it to the job queue. The workers will pick them up automatically and process them.
Once all jobs are sent, I close the job queue and wait for all workers to finish.
Same thing for the result queue — once results are all pushed, I close the queue and wait for the result processor to finish.
Now I print how long the total compression process took.
What Did I Observe?
After building everything, I ran the tool using:
go run main.goAnd here’s the output I got:

Let’s break it down:
Before starting, the memory allocation was practically zero — expected since nothing heavy had kicked off yet.
After compression, the memory allocation was 28 MiB, with total allocated memory reaching 30 MiB.
The system (Go runtime + buffers + allocations) used 35 MiB in total.
This was exactly in line with the MaxMemoryUsage I had set (32 MB). The memory cap + buffer reuse through sync.Pool+ semaphore control all worked together as intended.
The compression of 13 PDF files finished in just about 2.2 seconds, which is pretty fast considering everything was processed concurrently and memory was strictly controlled.
Important Links:
Final Thoughts:
I keep learning and posting new things here. You can subscribe to this newsletter. It’s FREE!
Was going through the code, good idea and nice implementation.
One thing maybe we can improve is that currently, within the compress function, we check if the context has been cancelled till that point or not, which is at the start of the compress function, and only then we start processing the file and compressing it.
If the user cancelled while the file is being processed midway, we will have to wait until that for loop is complete, even though we want it to be over sooner.